Hack.lu CTF 2025 UPPACKNING Writeup
I cannot honestly remember the last time I tried a heap pwning challenge that was actually fun. So it was very refreshing to play Hack.lu and find so many fascinating challenges. I looked at a couple of challenges, and they were all really good.
But, I spent most of the first day of the CTF looking at this UPPACKNING challenge and so this blog post will mostly be about that.
Let’s dive right in!
The challenge
The zip file for the challenge contains the two binaries that are involved as well as their source code. It also contains all the files for running the target in the docker environment which replicates the one deployed on the server.
It also contains the ynetd binary and its source code. Essentially, this binary acts as a socat alternative and is only used for spinning up all the binaries needed for this challenge. So, its not really relevant to the challenge.
Instead, the relevant binaries are main and worker. Once you connect to the server listening on port 1024, you are now communicating with the main binary. At the same time, a worker process is also spun up. This process doesn’t communicate with you directly but rather only talks to the main process.
For this purpose, the main process connects to port 9090 which ynetd is accepting connections on. Once it connects to this port, ynetd starts up the worker process. And now the main and worker talk to each other over port 9090.
To be precise, main only sends input to the worker process. The response from worker is handled by a pthread of the main process.
This will be important later!
So the main process spins off a thread which accepts inputs sent through the file-descriptor which is connected to the port 9090. This thread continuously loops and waits for messages on this file-descriptor. I’ll call this thread #2
The main thread (thread #1) listens on STDIN and offers a file-system like service where you can create/delete/list files and view/modify their contents. We are also allowed to uncompress the files which happens using a Zstandard (zstd) uncompression.
enum Commands {
Create,
Read,
Write,
List,
Delete,
Uncompress,
ReadUncompressed,
DeleteUncompressed,
Exit,
};
The compressed and uncompressed files are kept in separate arrays. We are allowed to read from and delete the uncompressed files, but we cannot modify the uncompressed files.
The uncompression happens in the worker process. When you request a file to be uncompressed, the thread #1 in the main process sends the contents of the compressed file to the worker process. The worker then uncompresses the file and sends it back to thread #2 in the main process which creates the uncompressed file with the new contents it received.
This communication between the main process and worker process occurs through a custom protocol.
The protocol
The source code for this protocol is provided which resembles a hybrid between TCP and UDP. There’s a limit to the amount of data that can be sent through this protocol at a time (which is <0xFD or 253). This means that larger files are split up into fragments before sending. And these fragments are reassembled upon reception.
It resembles TCP in the sense that each fragment contains a index value which specifies the index of this fragment in the large file. It resembles UDP in the sense that the sender does not check whether the receiver has responded with an acknowledgement or not. If an error happens during transmission, the receiver simply stops receiving packets and resets it state.
For files that are smaller than the limit, the entire file is sent as a whole. In order to differentiate between a fragmented file and a single file, the protocol uses the first byte of the data.
A value of 0 in the first byte indicates that this data contains the entire file. Whereas a value of 1, indicates that this data is a fragment of a larger file.
// Receiver side
void packetio_frame_receive(uint8_t *frame, size_t len, PacketIO_t *packet_io) {
if (frame[0] == Single) {
receive_frame_single(frame, len, packet_io);
} else if (frame[0] == Fragmented) {
receive_frame_fragmented(frame, len, packet_io);
}
}
...
// Sender side
void send_fragment_single(uint8_t *fragment, size_t len, PacketIO_t *packet_io) {
...
packet_io->send_buf[0] = Single;
...
}
...
void send_fragment_fragmented(uint8_t *fragment, size_t len, PacketIO_t *packet_io) {
...
packet_io->send_buf[0] = Fragmented;
...
}
If the data being sent is a fragment of a file, the second byte of the data indicates the index of this fragment. When the first fragment is being sent, this byte contains the total number of fragments that are expected.
// Receiver side
void receive_frame_fragmented(uint8_t *frame, size_t len, PacketIO_t *packet_io) {
...
if (packet_io->n_fragments == 0) {
packet_io->n_fragments = frame[1]; <------- Byte at offset 1 indicates total number of frames
...
}
...
// Sender side
void send_fragment_fragmented(uint8_t *fragment, size_t len, PacketIO_t *packet_io) {
...
packet_io->send_buf[0] = Fragmented;
if (packet_io->send_first_fragment == 0) {
packet_io->send_buf[1] = packet_io->send_n_fragments; <--------- Set here
packet_io->send_first_fragment = 1;
}
...
}
Once the first frame of a fragment has been sent, the next frame will contain frame indices starting from 0. The sender and receiver keep track of the total number of frames sent and they will stop when their counter becomes equal to total_frames - 1 (or total_frames - 2 in the case of the receiver).
// Receiver side
void receive_frame_fragmented(uint8_t *frame, size_t len, PacketIO_t *packet_io) {
...
int last = 0;
if ((packet_io->fragment_index + 2) >= (packet_io->n_fragments)) {
last = 1;
packet_io->n_fragments = 0;
}
...
}
...
// Sender side
void send_fragment_fragmented(uint8_t *fragment, size_t len, PacketIO_t *packet_io) {
...
if ((packet_io->send_fragment_index + 1) == packet_io->send_n_fragments) {
packet_io->send_n_fragments = 0;
return;
}
...
}
That pretty much sums up the important parts of the protocol.
Only thing left to do is to find the vuln, pwn and cat flag.
The vulnerability
Since the organizers provided the source code for this challenge, you’d think finding the vulnerability would be easy.
To be fair, Claude was able to find a buffer-overread when you read from an uncompressed file very quickly. This could be useful for memory leaks.
However, it took @zolutal and I around 12 hours to find a memory corruption bug. During that time, we came up with so many theories on what the vulnerability could be. In fact, we were convinced that it had to be a race-condition vulnerability.
At one point, I was absolutely certain that the vulnerability had to occur when the receiver was calculating packet_io->fragment_index + 2 since fragment_index was a uint8_t which would lead to an integer overflow.
However, this was not happening since the uint8_t was promoted to a 32 bit integer before the addition.
I was so full of myself and asked the organizers if there was a mistake in the challenge since no one had pwned it at that point. That was a very dumb move on my part.
However, after many more hours of talking to Claude and brainstorming possibilities, I finally found the bug.
So, when a file is being uncompressed, the worker uses a function ZSTD_getFrameContentSize to calculate how big the uncompressed file will be. As it turns out, you can just lie about the total size in the header of a compressed file and this function will happily return this fake value. And the actual uncompression (decompression?) can create a buffer with a smaller length.
Now, this fake size value returned by ZSTD_getFrameContentSize is used by the sender to calculate the number of fragments to be sent. This total number of fragments value goes in the second byte of the first frame sent.
int packetio_fragment_init(size_t max_len, PacketIO_t *packet_io) {
...
if (max_len > MAX_FRAGMENTS * packet_io->max_fragment_data) { // MAX_FRAGMENTS = 255
packet_io->send_n_fragments = 0; // max_fragment_data = 253
return 1;
}
packet_io->send_n_fragments = (max_len - 1) / packet_io->max_fragment_data + 1;
return 0;
}
However, once the sender start sending the frames, it uses the length of the buffer actually generated by the uncompression done by ZSTD_decompressStream. The sender stops sending any new frames when the total number of bytes it has sent becomes equal to the total number of bytes generated by the uncompression.
void send_fragment_fragmented(uint8_t *fragment, size_t len, PacketIO_t *packet_io) {
...
while (len != 0) {
uint64_t copy_len = MIN(len, packet_io->max_fragment_data - packet_io->send_buf_index);
memcpy(packet_io->send_buf + packet_io->send_buf_index + 2, fragment, copy_len);
packet_io->send_buf_index += copy_len;
fragment += copy_len;
len -= copy_len;
...
}
...
}
What this effectively means is that the sender can initially tell the receiver to expect N frames, but then only go on to send M frames where M<N.
Since the receiver doesn’t know that the sender has stopped sending frames, it will continue to wait for the M+1 frame to arrive.
At this point, if we send another file to be uncompressed, the sender will restart its process of calculating fragments and send the first frame of this new file with the new total number of fragments P.
Now, the receiver is expecting a value of M+1 in the frame index (byte offset 1), but it sees a frame with a value P. If P != M+1, this doesn’t follow the expected frame index and so the receiver resets its state after dropping this frame.
The sender however, goes on to send the next frame (which starts at index 0). When the receiver sees this frame, it assumes that the byte at offset 1 contains the total number of expected fragments which in this case is 0.
The receiver then allocates a buffer of size 0 to hold this frame (of length 0xFD) and then copies the first frame into this buffer. And boom! There’s our memory corruption.
It took me a little bit of time, trying to coax ChatGPT to give me a python script that generated a zstd compressed input which satisfies my requirements. And also some time to debug this multi-binary setup. But, around midnight, I had a Proof-of-Concept which replicates this buffer-overflow.
About time!!
The exploit
So far, we had a memory read and a memory write on the heap. And so we figured, it’d be an easy solve from this point onwards, right ? Thinking this, we passed off this challenge to one of the newer CTF members @Sammy.
However, there were quite a few more complications required to finish the exploit.
Since in this challenge, the thread #1 which allowed users to create compressed files was using calloc which does not use the tcache. However, thread #2 does use malloc, but it never free’s anything. All the deletion of compressed and uncompressed files happens within thread #1. Any pointer allocated by thread #2 was going into the tcache of thread #1 when it was freeing this pointer.
To summarize, in thread #1, we could not retrieve anything from the tcache. And in thread #2, we could not push more than one chunk into the tcache for each bin.
Unfortunately, we could not finish this challenge during the CTF. And so I spent my Sunday evening working on it.
I thought that the way to exploit this challenge would be to use fastbins and then fake a chunk in the stack which would allow me to get a ROP chain working. Since, you need to ensure that the FD of the fake chunk you’re trying to allocate is valid, you’re restricted to only allocating fake chunks on locations where you control at least 13 bytes. And one of the locations that you could control was the stack of the function that reads from the file descriptors. In fact, I found that the offset from the heap base of thread #2 to its stack had only 16 bits that were changing. So it could potentially be brute-forced in 65,536 attempts. Which is not too bad.
So I went down this rabbit hole of trying to get a fastbin in the stack of thread #2. After many hours, I had finally achieved my goal and had leaked the stack canary and could not overwrite the saved RIP of thread #2.
At this point, I realized the importance of planning ahead when I found that thread #2 was never returning from its loop of waiting for new messages. Even though thread #1 had the option to exit, thread #2 would just continue looping until its killed by the OS. This meant that my effort was wasted and I would never be able to trigger my ROP chain.
The better exploit
After I spent some amount of time reading the source code of malloc(which had changed quite a bit from the last time I read it, which was around 2020 or so), I realized that fastbins would be converted to tcache entries if their sizes matched.
So, if I had filled up the tcache bin in thread #1 with 7 chunks and had 3 chunks in its fastbin, the next call to malloc would move those three fastbin chunks into the tcache of thread #2.
With tcache, since we’re no longer constrained by the 13 controllable bytes requirement, I proceeded to allocate a fake chunk over the compressed file array. With this array, I could now arbitrarily read from any address since I controlled the data and size values for each file.
And from there, all I needed to do was to overwrite one of the function pointers which was being used as a callback by the protocol and change its value to system and request compressing a file that contained ;sh\x00 as its contents.
❯ python exploit.py
[*] '/tmp/chall/main'
Arch: amd64-64-little
RELRO: Full RELRO
Stack: Canary found
NX: NX enabled
PIE: PIE enabled
RUNPATH: b'.'
SHSTK: Enabled
IBT: Enabled
Stripped: No
[*] '/tmp/chall/libc.so.6'
Arch: amd64-64-little
RELRO: Full RELRO
Stack: Canary found
NX: NX enabled
PIE: PIE enabled
FORTIFY: Enabled
SHSTK: Enabled
IBT: Enabled
[+] Opening connection to localhost on port 1024: Done
$ ls
flag
ld-linux-x86-64.so.2
libc.so.6
main
ynetd
$ cat flag
flag{**********}
$
[*] Closed connection to localhost port 1024
Overall, this was a fun challenge and I really enjoyed solving it. As well as the other challenges from this CTF.
The files for this challenge are available here.
And my exploit script is here.
Extra Credit
Since I never got to try out the brute-force approach of guessing the pthread stack base from its heap address, I wanted to give it a shot and see whether or not it was actually possible.
And to test it, I created a simple C program that would allocate a heap pointer and a stack buffer and print out the start address of their respective segments by reading from /proc/self/maps.
void* thread_func(void* arg) {
char buf[0x100];
char *p = malloc(0x100);
if (!p) {
perror("malloc");
return NULL;
}
uint64_t stack_start = find_mapping_start((uint64_t)&buf);
uint64_t heap_start = find_mapping_start((uint64_t)p);
printf("%#lx\n", stack_start - heap_start);
free(p);
return NULL;
}
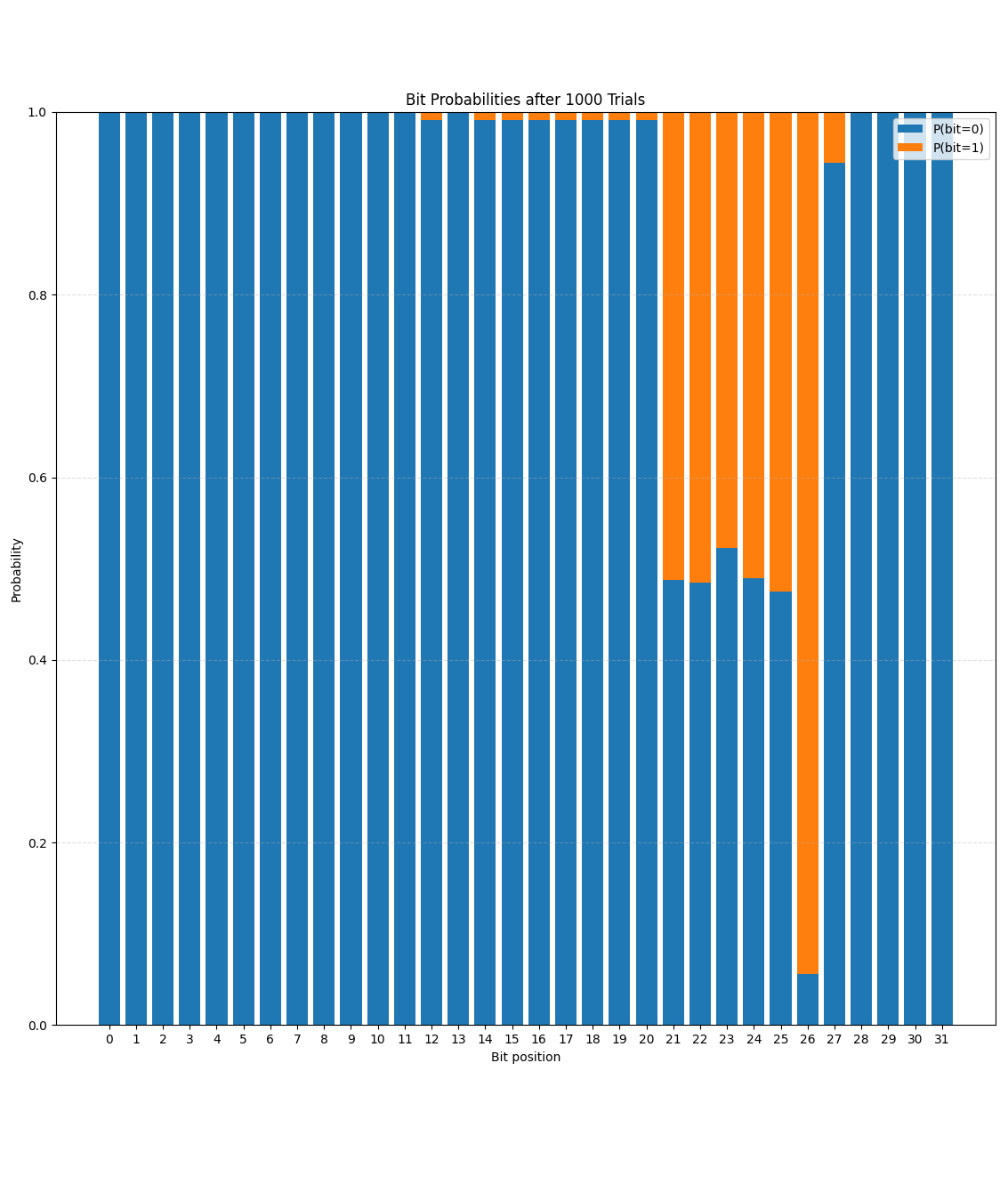
And I wrote a python script to run this program 1000 times and collect the offset values. And after analyzing the offset values, it turns out that there’s only 5 bits that are actually random in these offset values.
Now, what’s more fascinating is that the stack of this pthread is also contiguous with the libc base. Which basically means that if you have leaks of the heap in a pthread, you can predict addresses of its stack and libc within 32 attempts!!!
●→ 0x5555555553ad <thread_func+0000> endbr64 0x5555555553b1 <thread_func+0004> push rbp 0x5555555553b2 <thread_func+0005> mov rbp, rsp gef➤ vmmap $rsp [ Legend: Code | Heap | Stack ] Start End Offset Perm Path 0x00007ffff7400000 0x00007ffff7c00000 0x0000000000000000 rw- <----------- THREAD STACK gef➤ vmmap [ Legend: Code | Heap | Stack ] Start End Offset Perm Path ... 0x0000555555559000 0x000055555557a000 0x0000000000000000 rw- [heap] <----------- MAIN HEAP 0x00007ffff0000000 0x00007ffff0021000 0x0000000000000000 rw- <----------- THREAD HEAP ... 0x00007ffff73ff000 0x00007ffff7400000 0x0000000000000000 --- 0x00007ffff7400000 0x00007ffff7c00000 0x0000000000000000 rw- <----------- THREAD STACK 0x00007ffff7c00000 0x00007ffff7c28000 0x0000000000000000 r-- /usr/lib/x86_64-linux-gnu/libc.so.6
Here’s the probabilities for each bit in the offset from pthread heap base to stack base plotted.
And if you would like to run the same experiment, the files for it are available here
Enjoy Reading This Article?
Here are some more articles you might like to read next: